Outage RFO for September 6th/7th, 2019
Deutsche Übersetzung weiter unten.
Friday September 6th, the Selfnet core network was completely offline for a few hours. Getting the network back online took a few hours, but also led us down the wrong path. Because of that, more (but also shorter) outages followed. So what happened? Here's the Reason For Outage (RFO).
Volunteer Work
Selfnet is powered by 100% volunteer work. Friday morning in early September is probably the worst time for a big outage. Students are often not on campus, or when they are, they're preparing for exams. This of course also applies to the Selfnet folks. Early September is also a very busy time, because students move in and out of the dormitories, so there's a lot to do at the currently six Selfnet offices.
That means: an outage during those times is especially painful, because there is already a lot of work and few of us are here. So if you would like to join us, learn, experiment and build cool stuff with us, please don't hesitate to visit or email us!
Timeline
So here is what happend, in chronological order.
Thursday, around 9pm
We have been using Juniper EX4500 switches for our network core since we bought them in 2012. We also have some EX4600 which is a newer platform. They seem to have fewer bugs, better CPU, etc. and so we decided to replace the remaining EX4500. On Thursday, the two core switches "vaih-core-1" and "vaih-core-3" were replaced. We already have a few EX4600 and they run smoothly with the features we're using, so we didn't expect any issues.
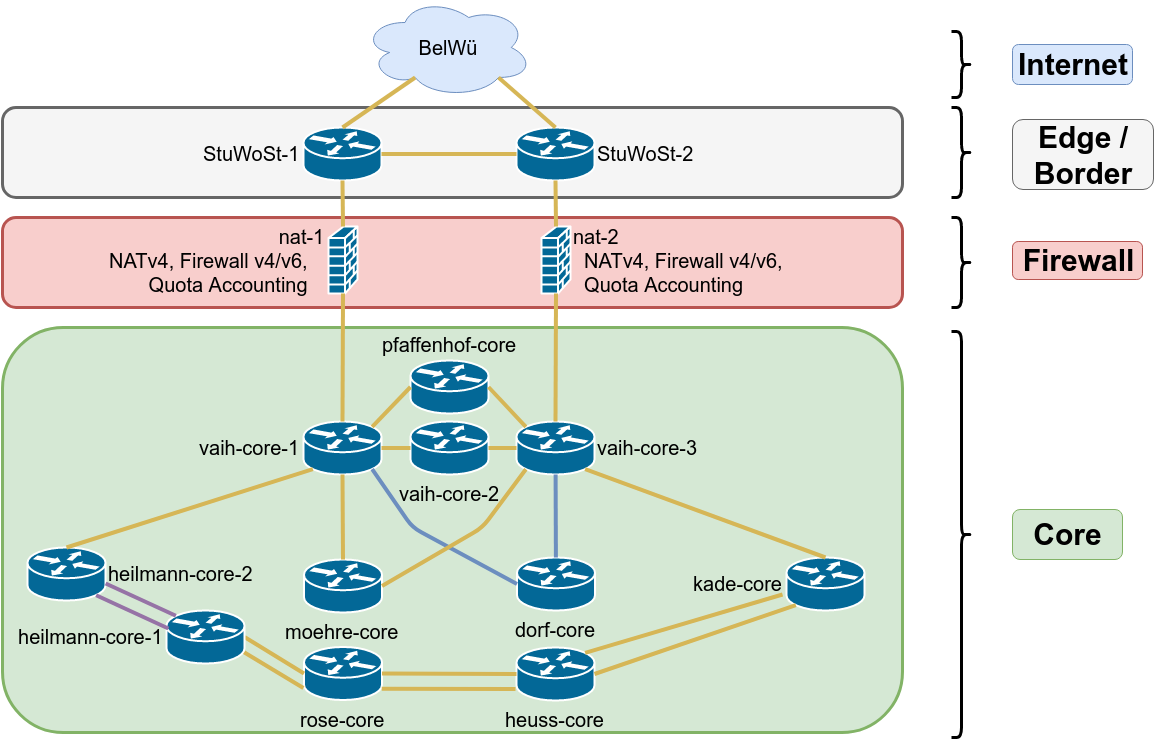
Selfnet Core Topology
As you can guess from the topology, everything should be redundant. Even the access switches are usually interconnected, so we can replace the core switches one by one, without any outages.
After the replacement, we didn't see any issues, everything was running fine as usual.

vaih-core-1/2/3 (top to bottom: EX4600, EX4500, EX4600)
Friday, 2:18am
Selfnet is suddenly offline. A few of us are still awake and try to find out what has gone wrong. As you can seen in the topology, there is enough redundancy and this should never happen.
Friday, 3:26am
There seems to be an issue with one of the NAT/firewall machines, traceroutes are stuck there and they don't seem to be forwarding traffic. nat-1 gets rebooted, but won't boot because of hardware issues. When nat-1 is finally back, the connection tracking daemon "conntrackd" doesn't start and needs manual intervention.
After some more debugging, the guys who were still awake gave up and went to bed.
Friday, around 6am
More people wake up. Since Selfnet is still offline, email, Jabber and IRC-chat aren't working. We're setting up an emergency communication IRC channel on another IRC network and create a CryptPad to collect all the information we have and coordinate work.
Friday, 8:57am
Someone is back on site. Routing looks fine, but traceroutes end at nat-2. The forwarding between core and edge routers seems to be broken, but routing still uses this path, as OSPF packets get though. The firewall nat-2 won't let anyone log in, probably because of high load or forwarding issues. As a last resort, nat-2 gets rebooted, too. Somehow this solves the problem.
We notice that the core switches have logged "DDoS violations". That could mean a storm of OSPF packets because of link flaps or duplicate packets introduced by forwarding issues.
We're not sure yet, why the forwarding stopped working, but let OSPF packets through, but for now Selfnet is back in business. Since the mailserver is back online, we're receiveing well over 100 emails from members with questions and complaints. So we start answering them, telling everyone that we had an outage, that it's working again, that we're still investigating the root cause and therefore might have another interruption.

Visualisation of new or open tickets in our ticket system (emails sent to support@selfnet.de) being rapidly answered by volunteering members.
Friday, between 9am and 10am
Still debugging the outage. The logs show recoverable memory issues (i.e. not hardware faults). So that would explain why a reboot solved the problem.
nat-1 gets a run of "memtest" to check the RAM banks for any physical damage, but it shows no errors.
Friday, 11:45am
Currently both IPv6 and IPv4 gets routed via nat-2. We usually split the traffic by address family, so nat-1 handles IPv4 and nat-2 handles IPv6 by default. They also sync their connection tracking states, so a failover won't damage any open connections and nobody will notice.
We're reverting back to splitting the traffic and moving IPv4 back to nat-1.
Friday, 2:20pm
Another outage. This time, only IPv4 is affected. nat-1 shows high CPU load, which is almost exclusively SoftIRQs. We analyzed this in a previous blog post (german) and the level of SoftIRQs is pretty much an indicator of the amount of traffic (packets per second) going through the firewall. This is either a hefty DDoS attack, a problem of nat-1 or packets bouncing back and forth between the routers.
For some reason, another reboot of nat-1 resolves the problem.
Friday, 10pm
The same problem now happens with IPv6 via nat-2. Again, SoftIRQs are at 80% (which, if you consider the impact of hyperthreading means about 100% hardware utilization).
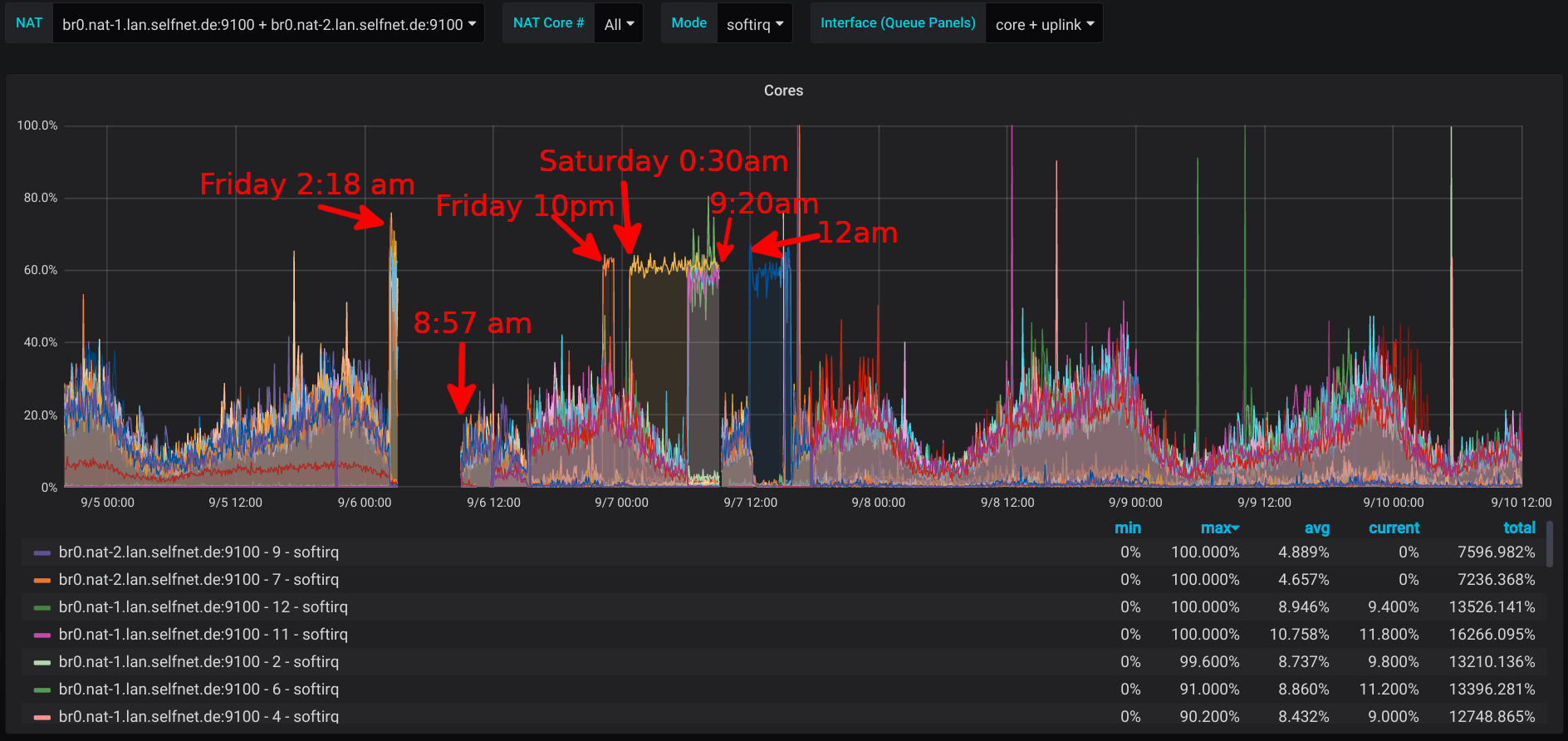
Screenshot of the Grafana SoftIRQ CPU usage monitoring
We already know that for some reason, a reboot can fix this, so we're rebooting nat-2, to get traffic flowing for the users, although this makes it harder for us to debug.
Traffic for both IPv4 and IPv6 is moved back to nat-2 now.
Saturday, 0:30am
SoftIRQs on both nat-1 and nat-2 are rising again, now both firewalls are again in trouble and the network gets unstable.
Saturday, 6am
Again, the firewalls collapse and the network is down.
Unfortunately, nobody is there to reboot the boxes, and since everything is down, we can't reboot the boxes remotely.
Saturday, 9:20am
Another reboot fixes the problem again.
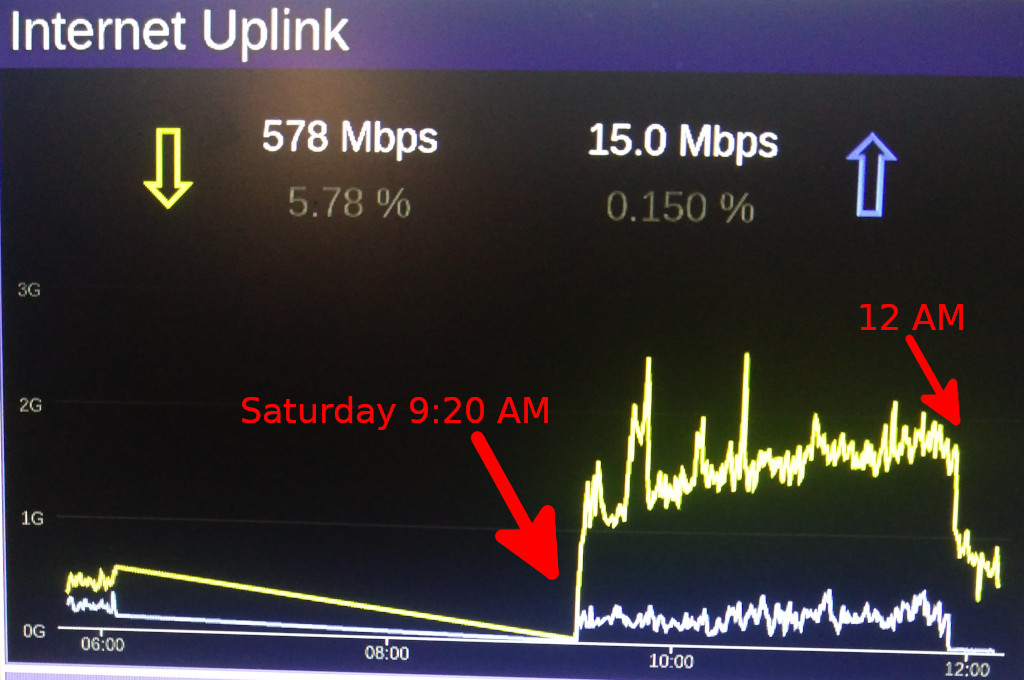
Uplink graph showing traffic increase when the problem is fixed (again) around 9:20 AM and another sharp drop in traffic volume at 12 AM.
Saturday, 12am
The issue is back again. We notice that both new core routers have high CPU utilization. The "Packet Forwarding Engine Manager", fxpc is using up all the resources. The other EX4600 in our network have a different (older) software version than the two new ones, so we decide that this might be another JunOS bug that was introduced in the new firmware. Sadly, this happens a lot with network vendor firmware. We decide to downgrade to the known good release that's running on the other EX4600s. During the downgrade, we see crashes and kernel dumps. The installation then fails due to filesystem erros. A complete reformat of the disks and a fresh installation finally gets them running again.
After both boxes have been downgraded, CPU utilization is back to normal, and fxpc is in the lower single-digit CPU percentage. Also, the OSPF issues are gone, the firewalls are working normal again, and we haven't seen this issue since.
So what happened?
It's hard to tell for sure, but we think that the Juniper boxes have a bug that's causing forwarding and OSPF issues. If you look at the SoftIRQ monitoring, it was always one CPU core that was overloaded during the outages. Usually the packets are load-balanced on all the CPU cores. The decision, which core to use is made on a per-flow basis, which means that a packets source and destination IP address and port and the protocol number are hashed. The hash sum is then used to point at one CPU core. If all packets have the same flow hash, they are all handled by the same CPU core.
Therefore we think that there had to be some kind of forwarding issue, where certain packets bounced back and forth between firewalls and core switches, until the link and single-core performance was saturated with handling those packets. Sadly, we focused on fixing this issue as quick as possible and didn't collect any packet dumps to analyze this issue further.
What now?
For now, the problem seems to be solved after the firmware downgrade. At the moment there is still an ongoing service request where Juniper is trying to resolve the problem - because although it is not really noticable - both new EX4600 core switches still have severe CPU utilisation spikes which does not look healthy.
But also (as we already noted in the NAT and firewall blog post) the firewall servers are a bit outdated. There are plans to replace them with new gear. We currently have demo equipment with modern AMD Epyc CPUs and 4x 10GbE NICs and will replace the old boxes soon.

AMD Epyc Demo Equipment for testing
There are also ideas to change the topology, so only user traffic passes the firewalls and server traffic goes to a separate DMZ.
Bericht über die Ausfälle vom Freitag und Samstag (6. und 7.9.)
Am Freitag Anfang September war das Wohnheimnetz für mehrere Stunden offline. Die Verbindung zum Internet wieder aufzubauen dauerte mehrere Stunden und hat uns erst einmal auf den Holzweg geführt. Deshalb folgten mehrere kürzere Ausfälle. Was war nun der Grund des Ausfalls?
Ehrenamtliche Arbeit
Der Selfnet e.V. wird zu 100% von ehrenamtlich aktiven Mitgliedern (Studierenden) getragen. Freitag morgens Anfang September ist vermutlich die schlechteste Zeit für einen Ausfall. Studierende sind aber nicht immer auf dem Campus bzw. wenn sie es sind lernen sie für Prüfungen. Das trifft natürlich auch auf die Mitglieder von Selfnet zu. Anfang September ist auch die Zeit zu der viele ins Wohnheim einziehen und dann Mitglied von Selfnet werden wollen und so lange Schlangen in den Sprechstunden entstehen.
Das beduetet: Ein Ausfall während dieser Zeit tut ziemlich weh, da sowieso viel Arbeit anfällt und wenige von uns Zeit haben oder überhaupt vor Ort sind. Wenn du also lust hast etwas neues zu lernen, zu experimentieren und coole Dinge mit uns zu bauen: Schreib uns einfach eine kurze E-Mail.
Zeitachse
Also was ist nun - zeitlich geordnet - passiert?
Donnerstag Abend gegen 21 Uhr
Seit ca. 2012 verwenden wir Juniper EX4500 Layer3-Switche um alle Pakete im Kernnetz (core) zu routen. Mittlerweile setzen wir auch schon seit 1-2 Jahren das Nachfolgemodell EX4600 ein. Technisch gesehen handelt es sich um eine ganz neue Technik und bis jetzt war der Eindruck: Weniger Fehler/Bugs, bessere CPU, etc. und deswegen haben wir entschieden 2 der bisherigen EX4500 zu ersetzen. Am Donnerstag wurden nacheinander "vaih-core-1" und "vaih-core-3" ersetzt. Die bisherigen EX4600 die wir einsetzen haben immer gut funktioniert und dementsprechend haben wir keinerlei Probleme erwartet.
Selfnet Core Topologie
Wie du vielleicht über die Topologie vermuten kannst ist alles Redundant. Sogar alle Access-Switche (also die Switche, an die die Zimmer direkt angeschlossen sind) sind üblicherweise an mehr als einem Core Switche angeschlossen und deshalb können wir diese Geräte auch austauschen ohne, dass ein Ausfall entsteht.
Direkt nach dem Austausch gab es keinerle Probleme. Alles schien gut zu funktionieren.
vaih-core-1/2/3 (von oben nach unten: EX4600, EX4500, EX4600)
Freitag 2:18 Uhr morgens
Selfnet ist plötzlich offline. Ein paar Selfnetter sind noch wach und versuchen herauszufinden was schief gelaufen ist. Wie du auf der Topologie sehen kannst: Das sollte nicht passieren. Der Ausfall eines einzelnen Gerätes sollte nie das gesamte Netz betreffen.
Freitag 3:26 Uhr morgens
Es sieht so aus als gäbe es ein Problem mit einer der NAT/Firewall Server. Traceroutes bleiben stecken und es scheint auch sonst kein Datenverkehr weitergeleitet werden. nat-1 wird neu gestartet, bleibt aber beim hochfahren aufgrund von Hardwarefehlern stecken. Als nat-1 schlussendlich hochgefahren ist verweigert "conntrackd" (der Dienst der für das Funktionieren von Netzwerkadressübersetzung / NAT notwendig ist) den Start.
Nach mehr Fehlersuche der noch "wachen" Mitglieder geben diese der Müdigkeit nach und gehen schlafen.
Freitag um 6 Uhr morgens
Mehr Mitglieder wachen auf. Da Selfnet immer noch offline ist, sind natürlich auch E-Mail, Jabber und der IRC-Chat außer funktion. Wir öffnen einen Notfall IRC Kanal in einem anderen IRC Netzwerk und erstellen ein CryptPad um alle Informationen zu sammeln und alles zu koordinieren.
Freitag um 8:57 Uhr morgens
Halbwegs ausgeschlafene Mitglieder sind vor Ort (Serverraum). Das Routing scheint in Ordnung zu sein aber Traceroutes enden bei nat-2. Das Weiterleiten von Paketen zwischen Core und Edge Routern (siehe Topologie) scheint kaputt zu sein aber das Routing nimmt trotzdem noch diesen Pfad, da die OSPF Pakete (Routing Protokoll) immer noch durch kommen. Die Firewall nat-2 lässt es nicht zu, dass sich jemand einloggt. Wir vermuten wegen hoher CPU-/System-Last und Problemen bei der Weiterleitung von Paketen. Als letzten Ausweg wird nun auch nat-2 neu gestartet. Unerklärlicherweise funktioniert jetzt plötzlich wieder alles.
Uns fallen in den Logs der Cores "DDoS violations" auf. Dies könnte an einem Sturm von OSPF Paketen (aufgrund von "link flaps") oder duplizierten Paketen durch die nicht funktionierenden Weiterleitung der Pakete liegen.
Wir sind noch nicht sicher warum die Weiterleitung von allen anderen Datenpaketen durch die NATs/Firewalls nicht mehr funktioniert hat obwohl OSPF Pakete weitergeleitet wurden. Da jetzt auch der Mailserver wieder online ist bekommen wir über 100 E-Mails von anderen Mitgliedern mit Fragen und Beschwerden zum Ausfall. Wir fangen an die E-Mails zu beantworten und teilen mit, dass es einen Ausfall gab, das es jetzt wieder funktioniert und wir immer noch nach der Ursache suchen.
Visualisierung von neuen und offenen Tickets (E-Mails an support@selfnet.de) die von ehrenamtlich aktiven Mitgliedern rapide beantwortet werden.
Freitag zwischen 9 und 10 Uhr morgens
Wir sind immer noch auf Fehlersuche. Die Logs zeigen "wiederherstellbare" Probleme mit dem Arbeitsspeicher (vermutlich also kein Hardware Problem). Das würde erklären warum ein Neustart das Problem gelöst hat.
nat-1 wird zur Sicherheit mit "memtest" geprüft ob der Arbeitsspeicher (RAM) physisch in Ordnung ist. Es werden keine Fehler gefunden.
Freitag um 14:20 Uhr mittags
Ein weiterer Ausfall. Dieses Mal ist nur IPv4 betroffen. nat-1 zeigt eine hohe CPU Last die hauptsächlich aus SoftIRQs besteht. Das haben wir schon einmal in einem vorherigen Blogeintrag analysiert und die Anzahl der SoftIRQs ist üblicherweise ein guter Indikator von hohem Verkehrsaufkommen (Pakete pro Sekunde, nicht Volumen) die durch die Firewall fließen. Es handelt sich also entweder um einen heftigen DDoS Angriff, ein Problem mit nat-1 oder Pakete springen zwischen den Routern hin und her.
Aus irgendeinem Grund löst ein Neustart von nat-1 das Problem.
Freitag 22 Uhr abends
Das selbe Problem tritt mit IPv6 über nat-2 auf. Wieder SoftIRQs bei 80% was - wenn man Hyperthreading bedenkt - etwa 100% Hardwareauslastung entspricht.
Screenshot aus unserem Grafana der SoftIRQ CPU Auslastung
Wir wissen schon, dass aus irgendeinem Grund ein Neustart das Problem löst. Also starten wir nat-2neu und die Daten unserer Mitglieder fließen wieder. Allerdings macht das die Fehleranalyse nicht unbedingt einfacher.
Der Datenverkehr wird jetzt für IPv4 und IPv6 gleichermaßen über nat-2 geleitet.
Samstag 0:30 morgens
SoftIRQs auf nat-1 sowie nat-2 steigen wieder an. Nun haben beide Firewalls wieder Probleme und das Netzwerk wird instabil.
Samstag 6 Uhr morgens
Wieder kollabieren die Firewalls und das Wohnheimnetzwerk ist offline.
Unglücklicherweise ist niemand vor Ort um die Firewalls neu zu starten und da alles offline ist können wir sie nicht aus der Ferne neustarten.
Samstag 9:20 Uhr morgens
Ein weiterer Neustart löst wieder das Problem.
Uplink Graph der zeigt wie sich nach wiederholter "Behebung" des Problems die Menge des übertragenen Datenverkehrs gegen 9:20 Uhr erhohlt und dann wieder um 12 Uhr stark einbricht.
Samstag 12 Uhr
Das Problem ist zurück. Wir bemerken das beide der neuen Core Router eine hohe CPU auslastung aufweisen. Der "Packet Forwarding Engine Manager", fpxc nutzt alle zur Verfügung stehende Ressourcen aus. Die anderen EX4600 die wir bis jetzt in unserem Netz eingesetzt haben verwenden eine andere - ältere - Firmware (Software) Version als die beiden neuen. Wir vermuten jetzt, dass es sich um einen Fehler von JunOS (Betriebssystem für Juniper Router/Switche) handelt der in einer neueren Version vorhanden ist. Leider passiert so etwas öfters bei Firmware von Netzwerkhardwareherstellern. Wir entscheiden uns für ein "Downgrade" zu der - bekanntlich - funktionierenden Version von JunOS die auf den bisherigen EX4600 schon gut funktioniert. Während des Downgrades sehen wir Crashes und Kernel Dumps. Die Installation schlägt dann mit Dateisystemfehlern fehl. Nach dem kompletten Neuformatieren der Festplatten und einer sauberen Installation funktioniert jetzt wieder alles.
Nachdem die Kisten auf die ältere Version downgegraded wurden ist die CPU Auslastung wieder normal und fxpc nutzt nur noch eine einstellige Prozentzahl der CPU. Auch die Probleme mit OSPF sind verschwunden, die Firewalls funktionieren wieder normal und seit dem haben wir auch keine weiteren Probleme beobachtet.
Also was ist passiert?
Im Nachhinein kann können wir leider nicht mit Sicherheit sagen, wo das Problem ganz genau lag. Wir vermuten aber, dass die Juniper Kisten einen Bug hatten, der die Forwarding- und OSPF-Probleme ausgelöst hat. Man kann im SoftIRQ Monitoring sehen, dass während den Ausfällen immer ein CPU Core überlastet ist. Normalerweise werden die Pakete in der Firewall auf alle Cores verteilt. Die Zuweisung, welcher Core für ein Paket zuständig ist, passiert pro Flow. Das bedeutet, die Source- und Destination-Adresse, sowie die Portnummern und die Protokollnummer werden gehasht. Die Hashsumme wird dann verwendet, um den Core auszuwählen, der das Paket verarbeitet. Wenn alle ankommenden Pakete den gleichen Flow Hash haben, werden sie vom gleichen Core verarbeitet.
Wir gehen deshalb davon aus, dass es ein Forwardingproblem gab, das dazu geführt hat, dass Pakete zwischen Core-Switch und Firewall hin- und hergeworfen wurden, bis der Link gefüllt und der CPU Core ausgelastet war. Wir haben uns leider sehr darauf konzentriert, das Problem zu lösen und haben dabei keine Packet Dumps gesammelt, die wir jetzt analysieren könnten, um den Bug genauer festzupinnen.
Was nun?
Kurzfristig scheint das Problem durch das Downgrade der Firmware behoben zu sein. Im Moment läuft noch ein offener "service request" bei Juniper in dem Juniper versucht das Problem zu beheben, denn obwohl man es nicht wirklich bei der Nutzung des Wohnheimnetzwerks merkt haben beide der EX4600 Core Switches immer noch regelmäßig Spitzen bei der CPU auslastung die nicht wirklich gesund aussehen.
Allerdings (wie wir schon im NAT/Firewall Blogartikel erwähnt haben sind unsere Firewall Server schon etwas älter. Es gibt schon Pläne diese mit neuer Hardware zu ersetzen und zur Zeit haben wir Testgeräte mit sehr modernen AMD Epyc CPUs und 4x 10 Gigabit Netzwerkkarten die vermutlich bald die alten Firewalls ersetzen soll da.
AMD Epyc Testhardware
Außerdem gibt es Pläne die Topologie zu ändern, so dass der Datenverkehr der Mitglieder und der Firewalls durch eine jeweils separate DMZ fließt.


 und 2 Access Switchen (Juniper EX3300) unterhalb eines Glasfaser Patchpanels.")
 / Glasfaserverteiler im Blockheizkraftwerk der PH")
 in der PH mit dem ein Multimode Faserpaar und ein Singlemode Faserpaar verbunden ist.")






