Die Selfnet-Firewalls und ihre Grenzen
Selfnet verwendet zwei Server für Firewall und NAT. In den letzten Tagen war die Internetanbindung durch diese Firewalls immer wieder mal etwas wackelig. Wir haben mal tief reingeschaut, was diese beiden Server machen, wo Bottlenecks sein könnten, und wie wir mögliche Performanceprobleme lösen können.
Wir wollen hier mal aufschreiben, was die Server machen, welche Probleme wir gefunden haben, und wie es weitergeht. Es wird also sehr technisch und detailiert!

Server als Firewall?
Bei Selfnet gibt es für alle User IPv4 und IPv6 Adressen. Bei IPv4 werden intern Adressen aus einem privaten Bereich pro Zimmer oder WLAN-Client vergeben. Jedes Mitglied hat eine öffentliche IPv4-Adresse. Es muss also eine Umsetzung, sprich Network Address Translation (NAT) passieren. Die Konfiguration für das NAT, für Portforwardings und für die IPv6-Firewall wird aus einer Datenbank generiert.
NAT und Firewall halten große Tabellen mit states der einzelnen Verbindungen. Grundsätzlich lässt sich das gut mit Servern machen. Die Last wird auf alle CPU-Kerne verteilt, für die Firewallregeln und state Tabellen ist im RAM genug Platz.
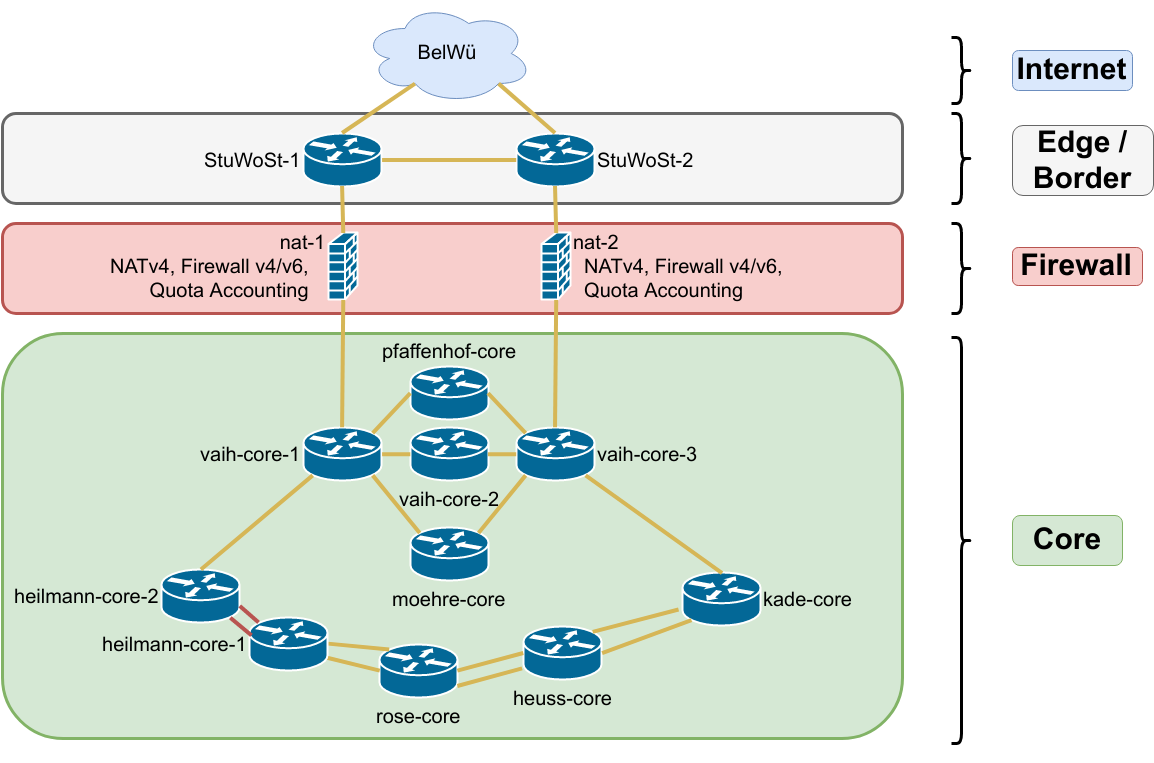
Selfnet Core Netztopologie
Die Firewalls sind im Netzwerk zwischen den Border-Routern (Uplink zum BelWü) und den Core-Routern in Vahingen eingebaut und firewallen damit ganz Selfnet. Um Redundanz für Ausfälle zu haben sind es zwei Stück. Eines macht primär IPv4 und eines macht primär IPv6. Beide synchronisieren die states mittels conntrackd, sodass ein Failover sehr wenig Impact hat.
Wo ist das Problem?
In den letzten Wochen haben sich mehrere Leute gemeldet und über hohe Round-Trip Times (RTT) geklagt. Die meisten davon sind Gamer, denen "ein hoher Ping" natürlich keinen Spaß macht. An manchen Abenden stieg die RTT über 300ms, was die Internetanbindung deutlich beeinträchtigt.
Durch hohe RTT dauern zum Beispiel TCP Handshakes länger, weshalb Websites langsamer laden, und der Datendurchsatz zum Beispiel bei TCP sinkt deutlich.
Intern war dieses Problem nicht sichtbar, nur vom/zum restlichen Internet. Zusätzlich waren hohe Latenzen im Spiel, was auf die Firewall schließen lässt. Die Router und Switche haben üblicherweise keine großen Buffer und können in unserem Fall maximal ca. 200ms RTT induzieren.
Was passiert da?
Das Leben eines IP-Paketes, das durch unsere Firewall geht ist... kompliziert.
Es landet erstmal im Receive Buffer der Netzwerkkarte und wird in eine Queue (max. 128, bei uns 16 wegen 16 CPU Threads) gesteckt. Die Karte löst einen Interrupt aus, damit die Pakete in der Queue vom System abgearbeitet werden. Dann kommt der Linux Kernel dran und arbeitet die Pakete in einem Soft-IRQ im Kernel-Space ab.

Packet Flow in Netfilter: jedes Paket durchläuft viele Stationen, an denen es geprüft, geroutet, verändert, getaggt oder genattet wird. Grafik von Jan Engelhardt, CC-BY-SA-3.0
Zunächst schaut conntrack nach, ob es zu einer Verbindung gehört, die schon bekannt ist. Dafür hält es eine Hashmap mit allen bekannten Verbindungen, macht darin einen Lookup und taggt das Paket zum Beispiel mit "established". Das ist wichtig, weil man damit ermöglichen kann, dass ein User von innen heraus eine Verbindung öffnen kann (z.B. zu einer Website), aber keine Verbindung von außen geöffnet werden kann, ohne dass der User das will. Eine klassische Stateful Firewall eben.
Danach kommen iptables Regeln, konkret Mangle und NAT. Hier gibt es Chains für jeden User, die z.B. eine User-ID an das Paket taggen und NAT machen, sofern die Regel oder conntrack das erlauben. Falls ein neuer Eintrag in conntrack entsteht, wird dieser mittels conntrackd auch auf die andere Firewall synchornisiert, sodass wir ein hot-standby haben. Die Regeln des iptables werden aus der User- und Netzdatenbank alle paar Minuten autogeneriert.
Wenn das alles geschafft ist, werden die User-IDs noch verwendet, um Traffic-Accounting (Info für den User) und um Traffic Shaping zu machen. Das Shaping greift eigentlich nur in zwei Fällen: entweder, wenn der Internetuplink an der Lastgrenze sein sollte. Dann wird versucht, die User mit viel Traffic zu bremsen, damit nicht ein paar wenige "bad guys" das Netz ausbremsen können. Oder ein User hat z.B. einen Testzugang, dann shapen wir aktuell auf ein paar MBit/s.
Scale
Derzeit (Dezember 2018) enthält die conntrack Tabelle zu Spitzenzeiten gut 200k Verbindugen. Auf der Primär-Firewall für IPv4 lasten dann gut 5 GBit/s (nach Innen) und 1 GBit/s (nach Außen) Traffic mit insgesamt knapp 700k Packets per Second (PPS).
Das Rule-Set für iptables ist rund 40MB groß und enthält 1,6 Mio. Regeln.
Bemerkenswert ist dabei, dass die beiden Firewall-Server mittlerweile seit über 8 Jahren im Einsatz sind und ursprünglich für ca. 2500 Selfnet-User konzipiert waren. Mittlerweile hat sich diese Zahl mehr als verdoppelt und die Server sind doch etwas in die Jahre gekommen.
Die Frage ist: Würde neue Hardware das Problem lösen? Trotz des Alters der Server sind diese technisch nicht schlecht: jeder hat 2 CPUs mit insgesamt 8 physischen Kernen, die bei 2,4 GHz takten. Wenn man sich Moore's Law anschaut, würde man in 8 Jahren einen Faktor 32 in der CPU-Leistung erwarten. Tatsächlich ist man im wirtschaftlich sinnvollen Bereich eher bei einem Faktor von 4 bis 8. Wie viele Jahre würden neue Firewall-Server halten, bis wir wieder an Grenzen stoßen?
Also was tun?
Eine Option wäre, potentere Hardware zu kaufen. Alternativ lassen sich vielleicht Optimierungen finden, die nochmal ein paar Prozent rausquetschen. Oder wir bauen Features aus, die nicht zwingend benötigt werden, bzw. lagern diese auf andere Systeme aus. Hm.
Ursachenforschung
Um informierte Entscheidungen zu treffen, wollen wir einmal ganz tief in die Firewalls reinschauen. Wo genau werden CPU-Zyklen verbraten? Gibts Features, die wir nicht (mehr) brauchen? Was wären die Anforderungen an neue Hardware?
Also: Was passiert bei einer Lastspitze? Offensichtlich ist schonmal: die RTT steigt, der Traffic sinkt, bzw. kommt im Mittel an eine Grenze. Gleichzeitig zeigt uns das Monitoring: die CPUs arbeiten weniger Interrupts pro Sekunde ab, befinden sich aber zu fast 100% im Interrupt-Handling. Die Load ist in diesen Momenten ungefär bei 8, was der Anzahl der cores (nicht Threads) entspricht. Die CPU Kerne peaken kurzzeitig bei 100% Last, sind im Mittel aber bei ca. 50% Idle bzw. 50% Soft-IRQ. Vermutlich ist Hyperthreading hier nicht hilfreich.
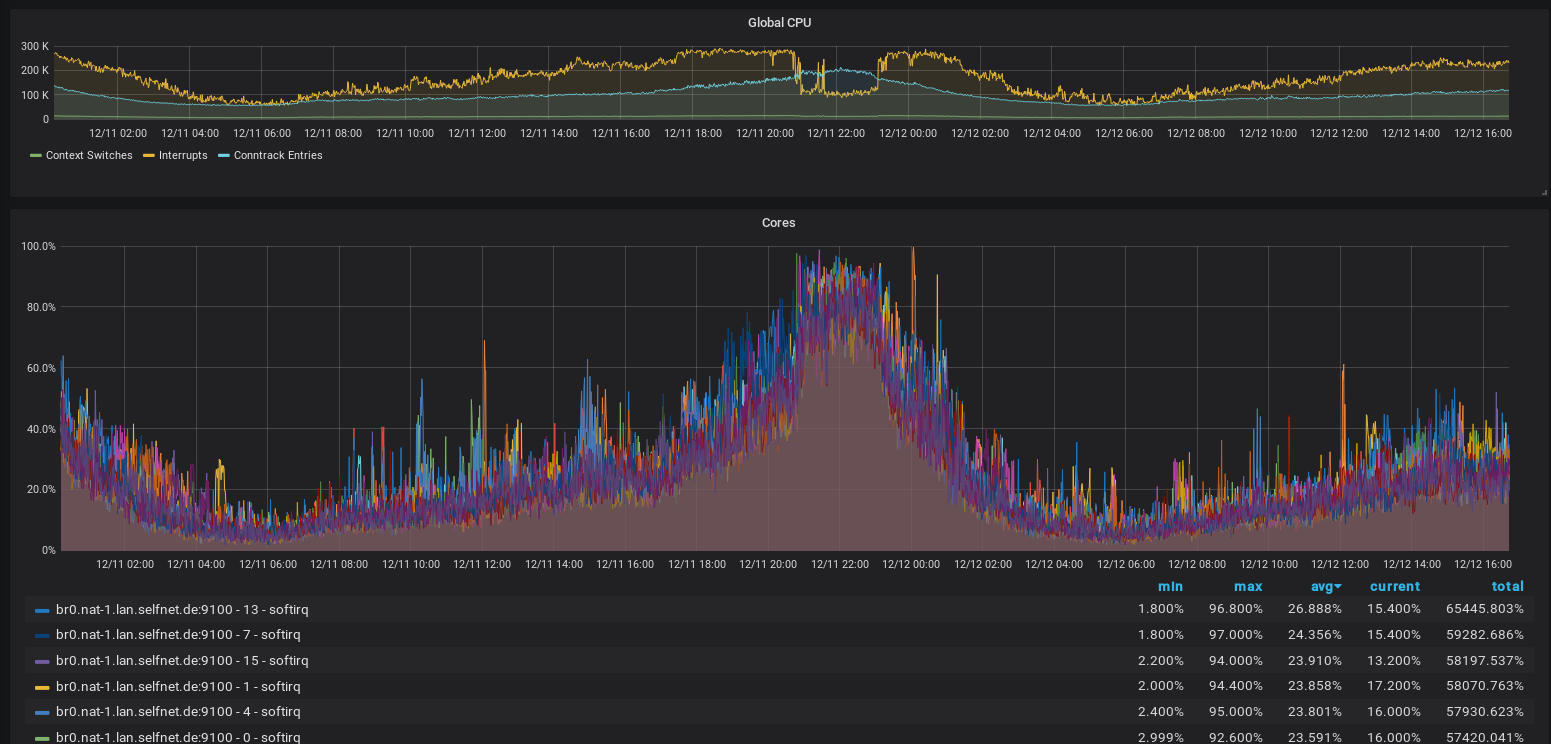
Interrupts: bearbeitete Interrupts pro Sekunde (oben, gelb) und Anteil an Interrupts der CPU-Zeit pro Core (unten)
Wir schließen daraus, dass die CPU-Cores ab einem gewissen Punkt die Pakete in einer Queue nicht mehr schnell genug abarbeiten können und deshalb länger in einem Interrupt bleiben. Prinzipiell bedeutet das weniger Context Switches und weniger Cache Flushes, was ein kleines bisschen Geschwindigkeit bringt, allerdings gibt es offenbar trotzdem den Punkt, wo die Queues sehr groß werden und dadurch hohe RTTs entstehen. Da sich das Gesamtsystem (inkl. der Clients) gewissermaßen selbst regelt, haben wir praktisch keine Packet Drops.
Warum dauert das in den Interrupts denn so lange?!
Praktisch unsere gesamte Packet Processing Pipeline findet im Kernel statt. Mit dem Tool perf top kann man gut sehen, in welchen Threads der Kernel sich am meisten aufhält. Wir haben vorher die CPU Taktfrequenz aufs Maximum festgenagelt. Damit sind die Zahlen ein guter Anhaltspunkt für die tatsächliche Hardwareauslastung.
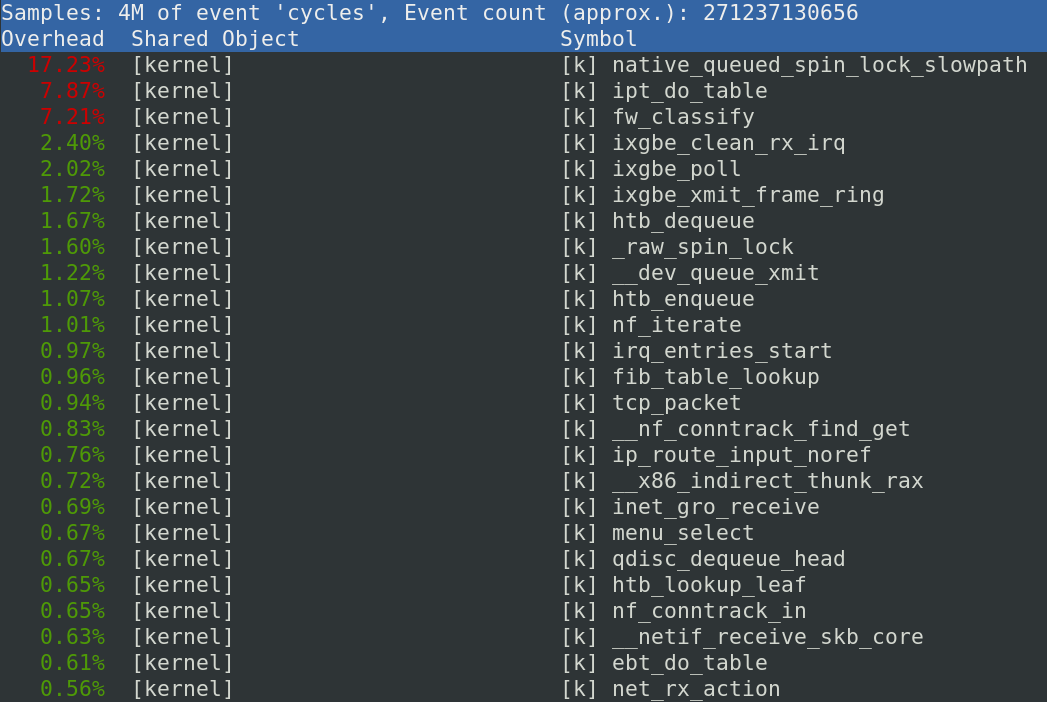
Output von
perf top: Zeigt die Kernelfunktionen, die die meisten CPU-Zyklen verheizen
Die beiden größten Zyklenfresser sind der Durchlauf des großen iptables Regelwerks und die tc shaper mit je ca. 15-20%, je nach Last. Nochmal gut 6% gehen für die Netzwerkkartentreiber ixgbe drauf und conntrack (inklusive seiner Funktion tcp_packet) macht nur ca. 4-5% aus. Dazu kommt noch ein bisschen Interrupt-Handling.
Zur Analyze einer hohen CPU Auslast sind FlameGraphs ein nützliche Darstellung. Mit einem "kurzen" 4-Zeiler kann damit ein Diagramm erzeugt werden, dass in der horizontalen Achse die verbrauchte CPU-Zeit und in der vertikalen Achse den Kernel-Funktionsnamen darstellt.
perf record -g -a; &
sleep 60;
kill %;
perf script | stackcollapse-perf.pl | sed -r "s/.*;(__do_softirq;.*)/\\1/;t;d" | flamegraph.pl > do_softirq.svg;
Da hier die Auslastung innerhalb des Linux-Soft-IRQ-Handler untersucht werden soll, werden nur Events betrachtet, die auf der Funktion __do_softirq aufbauen dargestellt.

FlameGraph für
perfvon__do_softirq
Wenn man diesen Graphen von unten analysiert, sieht man wie über verschiedene Wege fast immer in der Funktion ixgbe_poll des Intel-Netzwerktreibers landet. Diese Wege stellen interne Details des Soft-IRQ-Handlers da, die aber keine Auswirkung auf uns haben. Deswegen können wir diesen Graphen vereinfachen, indem ixgbe_poll als Basis verwendet wird.

FlameGraph für
perfvonixgbe_poll
Hier sind wir an der Basis unseres Netzwerkstacks angekommen. Leider können wir auf dieser Ebene nicht viel optimieren, aber wenn wir die einzelnen Türme vergleichen, fallen Ähnlichkeiten auf. Diese Türme scheinen alle auf nf_iterate zu basieren, weshalb wir hier nochmals reinzoomen.

FlameGraph für
perfvonnf_iterate
Dieser Graph scheint nun die CPU-Last der einzelnen Pakete zu sein. Die Blöcke lassen sich recht gut dem oben gezeigten "Packet Flow in Netfilter" Diagram zuordnen.
Hier sieht man schön, wie conntrack in etwa auf 10% des Aufwands kommt (inkl der iptables/nat Tabellen). Die Brigde kommt auf etwa 3%, die iptables Regeln so auf 7% und das NAT auf ebenfalls 7%. Die größten zwei Brocken mit über 50% verstecken sich hinter der Funktion __dev_queue_xmit (source).

FlameGraph für
perfvondev_queue_xmit
Hier handelt es sich um den Traffic-Shaper. Hier fallen zwei Probleme direkt auf:
Die Funktion fw_classify (source) verwendet 18% der Ressourcen des Shapers, um bereits markierte Verbindungen neu einzugruppieren. Das ist viel zu viel. Diese Funktion schafft es damit mit 7% der gesamten CPU-Zeit auf den dritten Platz vom Output von perf top. Grund dafür sind unsere derzeit gut 24.000 Shaperklassen. Der Kernel hat eine Hashtable, um die richtige Shaperklasse zuzuordnen. Allerdings ist die Größe der Hashtable nicht dynamisch, oder konfigurierbar, sondern auf 256 hardcoded.
Zusätzlich verschwendet die Funktion _raw_spin_lock (via inline __dev_xmit_skb) 40% der Ressourcen des Shapers. Spinlocks werden in der Multi-Core-Programmierung verwendet, um exklusive Funktionen zu synchronisieren, die nicht gleichzeitig ausgeführt werden dürfen. Aber das heißt leider, dass der Shaper nicht über mehrere CPU-Kerne skaliert und nur neue Hardware kaufen hier nichts helfen wird. Wir haben hier also eine Kombination aus einem (effektiv) single-threaded Shaper pro Interface-Queue, der viel zu Aufwändig eine Klassifikation der Pakete durchführt. Die teuren Funktionen des Traffic-Shapers (fw_classify, htb_enqueue, htb_dequeue und htb_lookup_leaf) laufen lasten wegen den Spinlocks unserer Vermutung nach ca. zwei CPU-Threads aus. Sie liegen aktuell bei ca. 170% CPU-Zeit eines Threads. Wir sind damit nah an der Leistungsgrenze und treffen hier auf das wohl kritischste Bottleneck. Auch neue Hardware mit mehr Cores bzw. Threads würde dieses Problem nicht lösen!
Die einfache Lösung ist das Abschalten der Shaper. Eine bessere Lösung ist es, den Shaper an allen Stellen zu umgehen, wo es möglich ist. Ein CPU Kern müsste für die Shaper aller Testzugänge mehr als ausreichen. Die beste Lösung jedoch wäre ein Shaper, der über mehrere Kerne skaliert. Leider scheint es da noch nichts zu geben, also bliebe nur selber schreiben, oder Linux/Netfilter/Intel-Entwickler dazu überreden... Wir fänden einen "TC Multiqueue-HTB Shaper" sehr hilfreich.
Parameter Tuning
IRQ-Mapping: Die Interrupts der Queues sollen auf alle CPU-Kerne gleichmäßig verteilt sein, damit sich alle an der Last beteiligen. Standardmäßig ist das offenbar nicht der Fall, weil so ein Linux-Rechner ja auch andere Dinge zu tun haben kann. Wir haben dafür ein Script, das einen Interrupt fest auf einen Core mappt. Man muss dafür Pakete wie irqbalance deinstallieren, sonst kommt das in die Quere. Das haben wir aber schon immer, da gibt's nix zu optimieren.
Hashtable Size: Für so eine Firewall muss man conntrack_max (die maximale Anzahl von getrackten Verbindungen) hochdrehen. Auch die conntrack_hashsize sollte erhöht werden. Bisher hatten wir 64k Buckets. Bei 200k Verbindungen sorgt das dafür, dass zunächst eine Suche in der Hashmap läuft und dann noch in einer Linked-List gesucht werden muss, weil in jedem Bucket mehrere Verbindungen liegen. Wir haben den Wert nun auf 1M erhöht, d.h. jede Verbindung sollte direkt über die Hashmap gefunden werden. Da die jetzt nicht mehr in den CPU Cache passt, haben wir gleich viele Cache Misses wie vorher, dafür ist der Lookup effizienter. Ersparnis: rund 1% CPU Zeit.
State-Sync: Der Service conntrackd synchonisiert die States mit der jeweils anderen Firewall über einen separaten 1G Link. Abschalten dieses Services ist eine Option, spart aber auch nur rund 1% CPU Zeit. Dafür wird aus dem hot-standby ein cold-standby. Lohnt sich also nicht.
Timeouts: Eine Verbindung, die ohne weitere Pakete Abbricht (z.B. weil er Client einfach ausgeht) wird in der Firewall weiter gehalten. Standardmäßig werden solche Einträge erst nach 5 Tagen gelöscht. Bei uns sind derzeit 12 Stunden eingestellt. Man könnte aber noch aggressivere Werte, z.B. eine Stunde, oder 30min verwenden. Wieviel das ausmachen kann, zeigt der Plot:
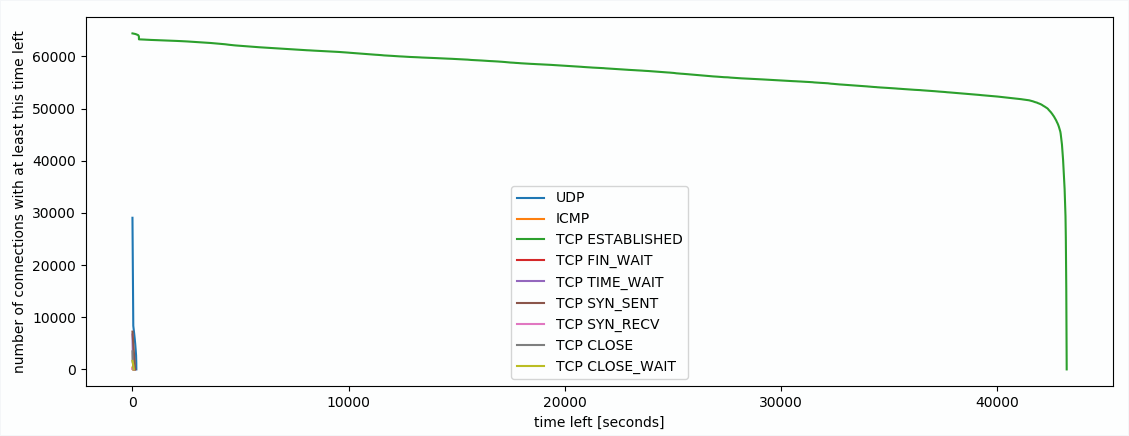
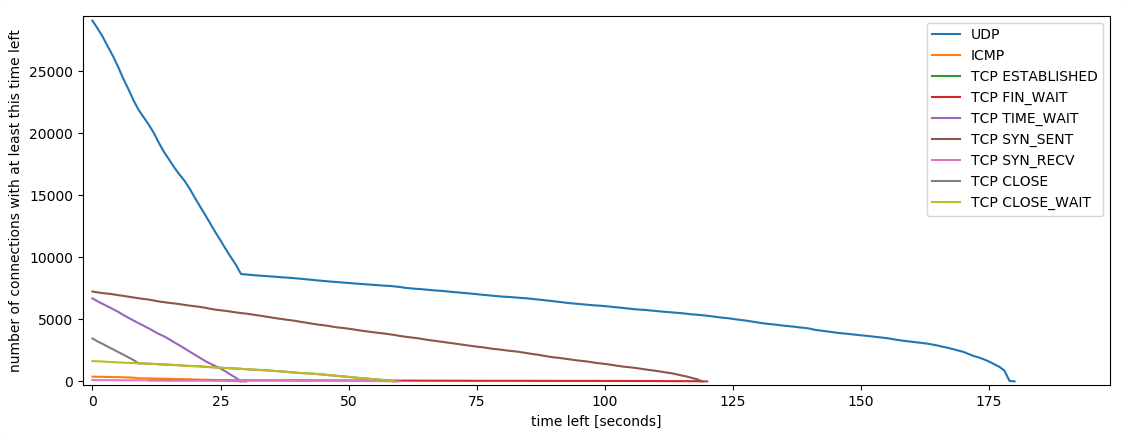
Plot der Anzahl der Verbindungen über ihre verbleibende Zeit im Tracking - an der linken Seite sieht man, dass viele Verbindungen bald gelöscht werden (z.B. wegen kurzen Timeouts bei UDP, oder weil sie geschlossen wurden), die grüne Linie sind aktive TCP Verbindungen
Wie man an dem eher horizontalen Teil der grünen Linie sieht, sind nur vergleichsweise wenige Verbindungen in einem langen Established Timeout offen. Würde man die Timeouts kleiner setzen, würde sich die grüne Linie nach links verschieben. Bei 1 Stunde statt 12 Stunden, würden knapp 10% gespart werden. Die 12 Stunden sind also ein sinnvoller Wert. Auch eine Stunde wäre wohl brauchbar, aber deutlich darunter (z.B. 5 bis 10 Minuten) würde schon Probleme bringen, weil Verbindungen rausfallen, die gar keine Leichen sind. Da die Verbindungen bis zu ca. 30-60min ungefähr linear abnehmen, deutet das darauf hin, dass Verbindungen älter als 30-60 Minuten fast nie wieder aufgenommen werden, sondern nach 12 Stunden timeouten. Diese aggressiver zu löschen würde auch bei Portscans oder Angriffen helfen.
Shaper: Die Shaper sind für uns nicht kritisch. Wenn wir sie abschalten, ist das schlimmste, was passiert, dass die Testzugänge nicht mehr gedrosselt sind. Aber vielleicht wollen wir das Shaping ja eh irgendwann abschaffen?
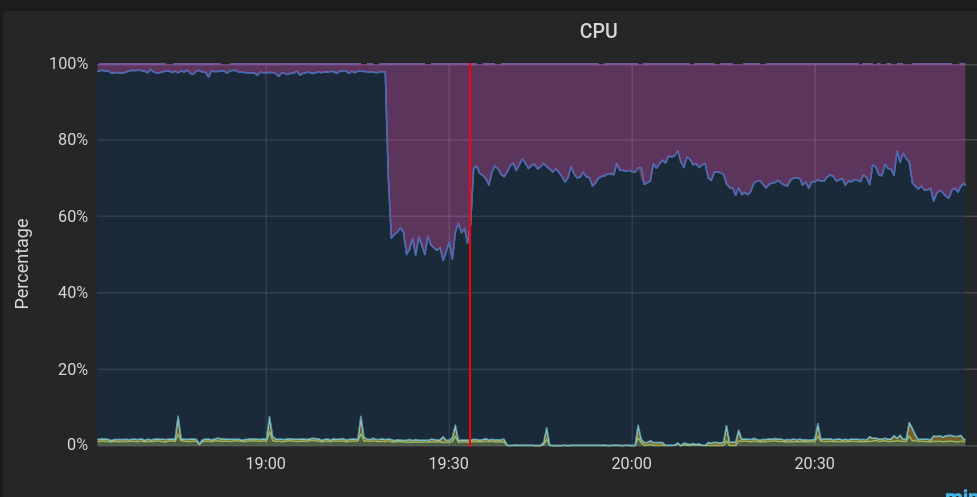
CPU-Auslastung: Last durch Soft-IRQ in Lila. Idle in Dunkelblau. Die rote Linie markiert die Abschaltung der Shaper.
Man sieht ganz deutlich, wie viel die Shaper ausmachen! Im Plot sieht man rund 20% mehr freie CPU Zeit. Zusätzlich gibts in den iptables Regeln noch Einträge, die Pakete flaggen, die nachher von den Shapern bearbeitet werden. Der Teil würde zusätzlich wegfallen, d.h. eine weitere kleine Einsparung bringen.
Firewallregeln: Unsere Firewallregeln werden autogeneriert. Die Templates und Scripte dafür sind eigentlich schon recht weitgehend optimiert. Beispielsweise sind die Regeln pro externe Adresse und pro Netzbereich in Chains aggregiert, sodass iptables nicht bei jedem Paket durch alle 1,6 Millionen Regeln laufen muss, sondern z.B. nach 10 Regeln in die Chain für den passenden Netzbereich abbiegt, nach weiteren 20 Regeln zur passenden User-Chain abbiegt und dort nurnoch wenige Regeln hat. Wir haben uns das angeschaut und Optimierungspotential gefunden. Beispielsweise wurde früher Traffic zur Uni Stuttgart separat gezählt. Das passiert heute nicht mehr, aber die Regeln dafür sind prinzipiell noch vorhanden. Auch die Markierungen für die Shaper können ggf. zukünftig abgeschafft werden. Außerdem hilft es, ganz oben in der FORWARD Chain die bereits akzeptierten (und damit in conntrack bekannten) Verbindungen direkt zu akzeptieren, damit die Regeln nicht durchlaufen werden müssen:
-A FORWARD -m state --state ESTABLISHED -j ACCEPT
Wir haben diese Optimierungen in den Firewallregeln direkt umgesetzt, um die aktuellen Probleme schnell zu lösen. Diese winzigen Änderungen bringen direkt einen großen Performancegewinn, wie man in dem Vergleich sieht:
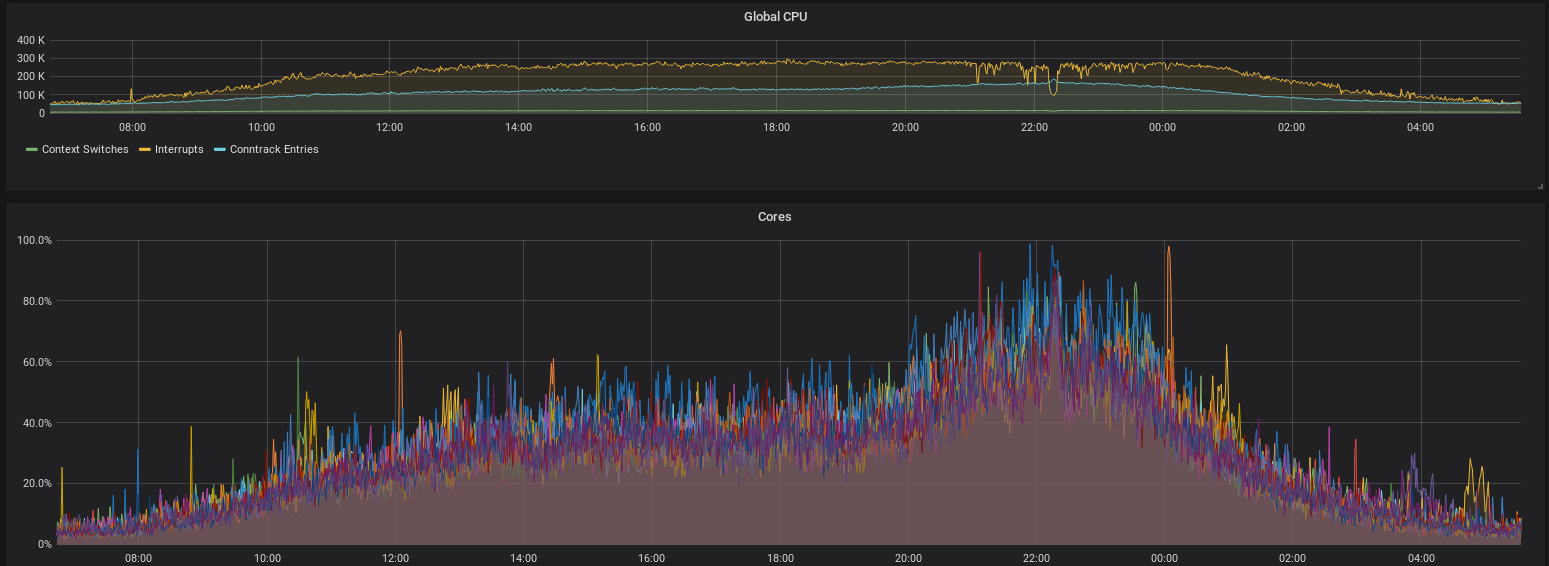
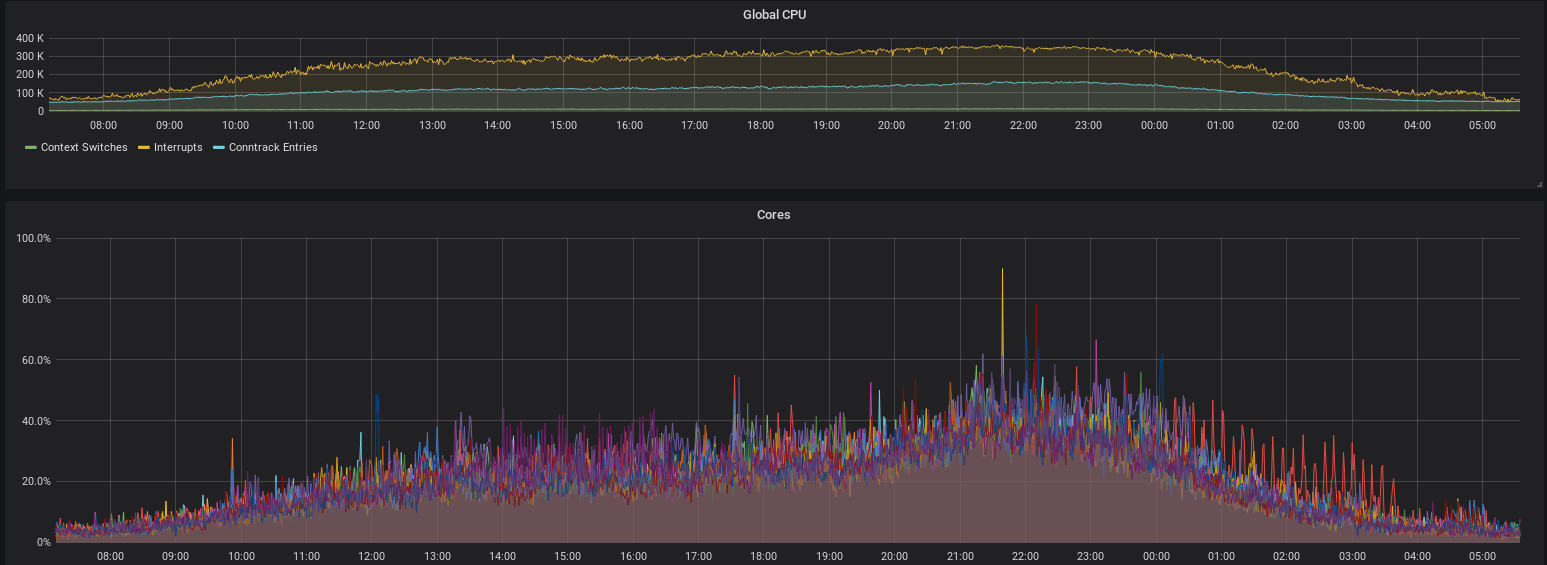
CPU-Auslastung durch Soft-Interrupts (unten) vor und nach den Optimierungen in den Firewallregeln. Auslastung (Traffic-Level) waren an beiden Tagen vergleichbar.
Solange die CPU nicht mehr komplett in Interrupts feststeckt, bzw. das TC Lock nicht mehr Zeit benötigt, als es hat, werden mehr Pakete abgearbeitet, als rein kommen. Damit baut sich keine Queue auf, und es gibt keine Probleme. Das Problem ist also vorerst (kurzzeitig) gelöst.
Wie geht's weiter?
Wir können mit einigen Optimierungen ca. 20-30% CPU Last einsparen. Das wäre die Hälfte der aktuellen Spitzenlast. Damit wäre kurzfristig wieder ein gutes Stück Kapazität auf den Firewalls vorhanden.
Offloading von mehr Arbeit in die Netzwerkkarte (z.B. mit XDP und eBPF) könnte auch nochmal einen guten Performance-Boost geben.
Zu guter letzt: Neue Hardware muss her. Die alten Firewalls haben treue Dienste geleistet, aber sind jetzt 8 Jahre alt. Mit neuer Hardware kann die Leistung nochmal deutlich gesteigert werden. Wo genau dieser Faktor liegt, hängt von sehr vielen Parametern ab. Wir schätzen aber, dass mindestens Faktor 4-10 bezahlbar sein sollte. Bei einer Hardwarebeschaffung wird auch auch der Schritt in Richtung 100 Gigabit interessant.
Wir werden vermutlich über die Weihnachtsfeiertage und zwischen den Jahren weiter an der Performance schrauben, aber parallel dazu auch die Beschaffung neuer Hardware planen. Wir werden berichten.
Dieser Beitrag wurde von Markus Wick und Sebastian Neuner verfasst.


 und 2 Access Switchen (Juniper EX3300) unterhalb eines Glasfaser Patchpanels.")
 / Glasfaserverteiler im Blockheizkraftwerk der PH")
 in der PH mit dem ein Multimode Faserpaar und ein Singlemode Faserpaar verbunden ist.")






