Dec 22, 2022
Deutsche Übersetzung weiter unten
A DHCP Server automatically allocates IP addresses to clients in a network using the Dynamic Host Configuration Protocol. If our DHCP Server fails, the clients in our LAN will not be able to get an IP address and can't connect to the internet. Therefore our DHCP Server is a crucial part of our infrastructure. While the Selfnet WLAN uses a FreeRADIUS Server to allocate IPs via DHCP, all WiFi Access Points get their IPs from the DHCP Server. So in case of a failure the WiFi is also affected.
In the past months we had quite a few problems with our old DHCP server. Until recently we used the ISC DHCP Server which is considered the industry standard. Since end of this year however ISC DHCP is end of life which means we won't get any updates or support, unless we pay the developers. Due to this we decided to migrate to a new DHCP server. The Kea DHCP Server is also developed by the Internet Systems Consortium and promises to be a drop-in replacement for ISC DHCP.
Since we don't want to manually edit the DHCP configuration every time a new member gets access to the network there is a Python script in place which generates the configuration automatically every 15 minutes by querying our PostgreSQL database. The old configuration was then generated using Jinja Templates. Our new scipt stores the configuration in Python data structures which get serialized to JSON which is required by Kea. A single subnet in the new configuration looks like this:
{
"subnet": "100.72.0.16/28",
"option-data": [
{
"name": "routers",
"data": "100.72.0.30"
},
{
"name": "domain-name",
"data": "user.selfnet.de"
}
],
"pools": [
{
"pool": "100.72.0.17 - 100.72.0.29"
}
],
"reservations": []
}
Every user gets a /28 subnet which consists of 16 IP addresses. Since the first IP (in this case 100.72.0.16) is the network address, the last IP (100.72.31) is the broadcast IP and the second to last(see option routers) is the Gateway IP to the switch we end up with 13 available IPs per user (this range is specified in the pool field). Additionally users have the option to get a public IPv4 address and forward ports to a device in the local network using MySelfnet. To ensure the device receives external traffic the local IP has to stay the same. This is done through the reservations field by specifying the MAC address of the device.
Additionally a few global options are specified for all subnets:
"valid-lifetime": 43200,
"max-valid-lifetime": 86400,
...
"option-data": [
{
"name": "domain-name-servers",
"data": "141.70.124.5"
},
{
"name": "ntp-servers",
"data": "141.70.124.2"
}
],
"next-server": "141.70.126.60",
"server-hostname": "netboot-1.server.selfnet.de",
"boot-file-name": "/pxelinux.0",
The IP address allocated to a client is always valid for 24 hours (max-valid-lifetime) and clients are supposed to renew the allocation after 12 hours (valid-lifetime). Besides the IP itself the response from the DHCP server also contains some additional information such as the IPs of our DNS and NTP-Servers. The last three lines advertise our netboot server which can be used to install a new operating system directly from the network.
This configuration is generated for around 6800 subnets and contains 700000 lines of text. To ensure high availability our DHCP Servers run redundantly as a pair, so if one server fails the other one takes over. After implementing and testing the new DHCP server over the last few months we migrated on December 8th. Since our old DHCP server ran redundantly as well, we were able to migrate one by one which kept downtime to a minimum.
Besides the DHCP migration there are a lot of other projects we're currently working on. We're always happy about new volunteers joining us to help with existing projects or to realize new ideas. You're welcome to join us in our Vaihingen office on Monays and Thursdays during support hours.
The Selfnet-Team
Deutsche Übersetzung
Migration unseres DHCP Servers auf Kea
Ein DHCP Server ist für die automatische Allokation von IP Adressen an die Clients zuständig. Wie der Name sagt, geschieht das über das Dynamic Host Configuration Protocol. Wenn unser DHCP Server nicht funktioniert, bekommen die Clients im LAN keine IP Adresse und kommen nicht ins Internet. Daher ist die dauerhafte Verfügbarkeit des DHCP Servers essenziell für uns. Das Selfnet WLAN hat einen separaten FreeRADIUS Server, der die Allokation der IPs über DHCP übernimmt. Da jedoch die Access Points ihre IP Adressen über den DHCP Server bekommen ist das WLAN von einem Ausfall des DHCP Servers auch betroffen.
In letzter Zeit hatten wir häufiger mal Probleme mit unserem alten DHCP Server. Bisher haben wir den ISC DHCP Server verwendet, der allgemein hin als Industriestandard gilt. Seit Ende diesen Jahres ist der ISC DHCP Server jedoch End of Life, bekommt also keine Updates oder Support mehr. Firmenkunden können sich verlängerten Support erkaufen, wir als Studentennetzwerk wollen das aber nicht und da der DHCP Server aktuell sowieso in regelmäßigen Abständen ausgefallen ist und neu gestartet werden musste, haben wir die Gelegenheit ergriffen und auf einen neuen DHCP Server migriert. Der Kea DHCP Server wird ebenfalls vom Internet Systems Consortium entwickelt und soll ein vollwertiger Ersatz für den alten DHCP Server sein.
Da wir die Konfiguration des DHCP Servers nicht manuell anpassen möchten, sobald wir ein neues Mitglied an das Netzwerk angeschlossen haben, wird die Konfigurationsdatei alle 15 Minuten automatisch generiert und bei Veränderungen auf den DHCP Server kopiert. Grundlage dafür ist unsere PostgresSQL Datenbank, auf der die Subnetze aller Mitglieder hinterlegt sind. Um die Konfiguration zu generieren, werden in einem Python Skript die betreffenden Daten mit einer SQL Abfrage aus der Datenbank abgerufen und in Python Dictionaries gespeichert. Die alte Konfiguration wurde daraus mithilfe von Jinja-Templates generiert. Da der neue DHCP Server die Konfiguration im JSON Format erwartet, wird die Datenstruktur direkt serialisiert. Ein Subnetz der Kea Konfiguration sieht so aus:
{
"subnet": "100.72.0.16/28",
"option-data": [
{
"name": "routers",
"data": "100.72.0.30"
},
{
"name": "domain-name",
"data": "user.selfnet.de"
}
],
"pools": [
{
"pool": "100.72.0.17 - 100.72.0.29"
}
],
"reservations": []
}
Wir stellen jedem User ein /28 Subnetz zur Verfügung, das Subnetz ist also 16 IP Adressen groß. Dabei ist die erste IP Adresse (hier 100.72.0.16) die Netzwerk Adresse, die letzte ist die Broadcast Adresse (100.72.0.31) und die vorletzte ist die Gateway Adresse zum Switch (hier als Option routers mit 100.72.0.30 angegeben). Es bleiben also 13 Adressen für den User übrig (das ist hier im pool angegeben). Über das MySelfnet Portal hat man die Möglichkeit, Geräten eine öffentliche IPv4 Adresse zuzuweisen und Ports freizuschalten. Dafür muss die IP Adresse des betreffenden Gerätes im lokalen Netz gleich bleiben. Daher können unter reservations MAC-Adressen angegeben werde, die immer die selbe IP bekommen sollen.
Zusätzlich gibt der DHCP Server noch ein paar Informationen an alle Subnetze weiter:
"valid-lifetime": 43200,
"max-valid-lifetime": 86400,
...
"option-data": [
{
"name": "domain-name-servers",
"data": "141.70.124.5"
},
{
"name": "ntp-servers",
"data": "141.70.124.2"
}
],
"next-server": "141.70.126.60",
"server-hostname": "netboot-1.server.selfnet.de",
"boot-file-name": "/pxelinux.0",
Die IP Adresse die ein Client erhält ist immer für 24 Stunden gültig max-valid-lifetime, wobei die Clients üblicherweise bereits nach 12 Stunden mit dem DHCP Server kommunizieren (valid-lifetime) um die Laufzeit der Zuweisung zu verlängern. In der Antwort des DHCP Servers wird neben der IP Adresse auch unser DNS und NTP-Server angegeben. Zudem wird mit den letzten drei Optionen ein Netboot Server angegeben, über das jedes Gerät im LAN ein neues Betriebssystem über das Netzwerk installieren kann.
Diese Konfiguration wird für ca. 6800 Subnetze generiert und umfasst ca. 700000 Zeilen. Um hohe Verfügbarkeit sicherzustellen laufen die DHCP Server als High-Availability Paar, sodass ein zweiter Server übernimmt falls der erste ausfällt. Nachdem wir die neue Konfiguration in den letzten Monaten implementiert und in ein paar Wohnheimen getestet haben wurde der DHCP Server am 8.12. in den laufenden Betrieb migriert. Da wir den alten DHCP Server auch redundant betrieben haben, konnten wir erst einen und dann den anderen DHCP Server migrieren, ohne dass es zu größeren Ausfällen kam.
Neben dem DHCP Server stehen aktuell noch zahlreiche weitere Projekte an, für die wir uns über Unterstützung freuen würden: Den Switch-Tausch im Laufe des nächsten Jahres, das Upgrade der WLAN-Gateway, der Ausbau unseres Monitorings, etc. Wenn du Interesse hast, an den Projekten mitzuwirken oder eigene Ideen umzusetzen, komme gerne Montags oder Donnerstags zu unseren Support-Stunden nach Vaihingen in unser Büro. Wir freuen uns immer über Freiwillige, egal ob technisch versiert oder nicht.
Das Selfnet-Team
Mar 11, 2022
Deutsche Übersetzung weiter unten.
New switches needs our LAN(d)
In 2021 we did not have a lot of "big" technical projects because of the covid pandemic. But right with the start of 2022 we started our process to chose new hardware for our network. The needed access hardware is used to connect our members in the dormitory to our network. In total we will need around 260 devices to cover everything.
Our current hardware is way over their expected lifetime but before there was no reason to change them from a technical perspective. We did not see any real innovations on the market until now. Also the first devices started to fail due to age related problems like failed fans, failed power supplies and failing storage chips. Also the vendors support will end in 2024 so we would not be able to fix any software issues or security vulnerabilities afterwards. Furthermore several new (larger) dormitories will be connected to our network which will need additional devices.
Therefore we are now at the perfect point of time to discuss a new access switch model. Of course we also want to integrate the new technologies of these platforms while we are at it. On the road map are features like being able to use multi-gigabit network devices or the Selfnet-PPSK-WLAN (currently in planning) which may allow to create a layer 2 network connection between the Selfnet WLAN and the network in the dormitory rooms. This would present the possibility to use in-room-streaming or using local wireless printers in your room.
Oh but all the choices to make...
In January we started to send our critera (which we created before) to different network vendors/suppliers. We expected to get back a suggested model and a short (at least by Selfnet standards) questionarie. We selected several vendors that were able to meet our criteria. This step is already completed and the vendors are currently providing us with demo equipment which we will test accordingly.
The vendors we selected are: Arista, Aruba/HP, Extreme Networks, Huawei und Juniper.
For each we selected models that provide all the features we asked for. That is mainly the multi-gigabit ports and VXLAN as an overlay feature. All features we currently use are set as basic requirements.

Current Demo Equipment (Top: Juniper EX4400, Middle: EX3300 (current model we use), Bottom: Arista 720XP)
This procedure is an interesting exercise in knowledge transfer as - even for us - it is not usual to have that many different models and vendors on our hands for experimenting.
It will still take several weeks until our tests are finished, propably until the end of May. Hopefully we can also integrate some devices into our active network to see how they behave in "real world" conditions. It is possible that we will replace access switches on a short notice (mainly the Vaihingen area).
But as we are volunteers working in our spare time we cannot provide any finished "timetable". But this also means: If you're interested in tech and/or networking you can just drop by and help out. We're always looking for interested people who want to join us, and shape our network.
We hope to have a decision within this year and maybe get the first new devices to install - but as soon as we know more about this, there will be another update.
Deutsche Übersetzung
Im Jahr 2021 haben Pandemiebedingt im Verein technisch wenig große Umsetzungen stattgefunden. Frisch zum Jahresbeginn 2022 haben wir mit der Auswahl neuer Hardware für Access-Switche begonnen. Dies sind die Geräte, mit denen wir die Anschlüsse unserer Mitglieder in den Wohnheimen bereitstellen. Insgesamt geht es dabei um eine Menge von circa 260 Geräten.
Die alten Geräte sind mittlerweile deutlich länger als die geplante Laufzeit in Betrieb. Bisher gab es jedoch keinen technischen Grund die Geräte zu tauschen. Deutliche Technologie-Neuerungen gab es auf dem Markt in den vergangenen Jahren nicht. Mittlerweile hat sich diese Situation geändert und es gibt vermehrt technische altersbedingt auftretende Probleme. Dazu gehören defekte Lüfter, Netzteile und ausfallende Speicherelemente.
Auẞerdem wird der Softwaresupport für die eingesetzten Geräte Mitte 2024 enden. Sicherheitsprobleme könnten danach nicht mehr auf unseren alten Geräten behoben werden. Zusätzlich werden in den nächsten Jahren auch mehrere größere Wohnheime mit einem Bedarf an weiteren Geräten angeschlossen.
Dementsprechend sehen wir nun genau den passenden Zeitpunkt um über ein neues Modell zu diskutieren. Soweit es uns möglich ist wollen wir gleichzeitig versuchen neue Technologien mit der neuen Plattform zu integrieren. So stehen auf dem weiteren Horizont beispielsweise die Nutzung von Multi-Gigabitanschlüssen oder die Verbindung zu einem in der Planung befindlichen Selfnet-PPSK-WLAN. Mit der richtigen Technologie auf den Switchen könnten dann Layer 2 Verbindungen zwischen Selfnet WLAN und Zimmernetzen hergestellt werden. Das ermöglicht das einfache Streamen oder drucken aus dem WLAN an Geräte, die im Zimmer angeschlossen sind.
Wer die Wahl hat....
Im Januar haben wir die von uns lange erarbeiteten Kriterien an die verschiedenen Gerätehersteller versendet. Als Antwort haben wir einen Modellvorschlag und einen ausgefüllten kurzen (für Selfnet verhältnisse :) Fragebogen erwartet. Aus diesen Antworten haben wir Hersteller ausgewählt, die unseren Anforderungen entsprechen. Inzwischen ist der Schritt abgeschlossen und die ausgewählten Hersteller stellen uns aktuell Testgeräte zur Verfügung. Die Geräte werden dann von uns auf verschiedene Aspekte getestet.
In die engere Auswahl geschafft haben es fünf Hersteller: Arista, Aruba/HP, Extreme Networks, Huawei und Juniper.
Jeweils haben wir uns für die Tests für Modelle der Hersteller entschieden, die alle unsere Wunschfunktionen an neuen Features unterstützen. Dabei geht es vor allem um Multigigabit auf allen Ports, sowie um die Funktion VXLAN. Die bereits eingesetzten Funktionen werden von uns natürlich als Grundlage erwartet.
Momentanes Testequipment (Oben: Juniper EX4400, Mitte: EX3300 (Momentanes Modell), Unten: Arista 720XP)
Der Gerätetest ist natürlich für uns ebenfalls eine Interessante Angelegenheit aus dem Bereich der Wissensvermittlung. Die Gelegenheit mit so vielen verschiedenen Switchmodellen und Herstellern zu experimentieren gibt es bei uns auch nur selten.
Bis die Tests abgeschlossen sind wird es noch vermutlich mehrere Wochen dauern. Die letzten Geräte werden vermutlich bis in den Mai bei uns sein. Optimalerweise werden wir die Geräte auch testweise ins aktive Netz integrieren um das Verhalten unter "realen Bedingungen" zu beobachten. Möglicherweise kann es daher bei einigen Wohnheimen (vor allem am Campus in Vaihingen) einige kurzfristige Gerätewechsel geben.
Da wir aber letztendlich alle ehrenamtlich und in unserer Freizeit diese Arbeit übernehmen, kann man hier leider keinen festen Zeitplan definieren. Das heißt aber auch, dass jeder der sich für das Thema interessiert gerne bei uns vorbei schauen und mit helfen kann. Wir suchen immer interessierte Leute, die das Netzwerk mitgestalten wollen.
Prinzipiell hoffen wir das noch dieses Jahr eine Entscheidung getroffen wird und vielleicht auch schon die ersten Geräte eingebaut werden können. Sobald wir so weit sind wird es noch eine genauere Ankündigung geben.
Jan 01, 2021
Deutsche Übersetzung weiter unten.
Our "new" network map is public now which shows the current situation in our (internal) network.
But we also want to describe the path how this project came into existence.
Some years ago several members visited the Gulasch-Programmier-Nacht in Karlsruhe. As a project there they used a Javascript-Library VivaGraphJS, which is a graph rendering engine also used to display molecules, to visualize networks.
Originally the just wanted to know how our network "looks". The point about the funny movable map that resulted from the rendering engine naturally increased the fun factor.
Some years later another member built a Perl script (because he wantet to learn Perl) to scan our internal network automatically and collect the neighor relations between the devices.
This script utilizes SNMP queries to our devices and asks for the LLDP Neighbors.
SNMP (Simple Network Management Protocol) is usually used by us to check for usage informations like temperature, cpu usage or network traffic. But it can (with sufficient privileges) also query a lot more information.
This information includes the LLDP (Link Layer Discovery Protocol) data of the device. LLDP is utilizing a lower network layer between configured devices (even before using IP addesses) to exchange basic information between devices. It includes the hostnames or the connected ports. So this can also used to find physical faults in connections.
An Example
Local Interface Parent Interface Chassis Id Port info System Name
ge-0/1/2.0 - xx:xx:xx:xx:xx:xx ge-0/1/0.0
These resulting script data was just used to find missing links or single points of failure (via a script).
The last years we connected those two projects in our network map. The first versions are from 2016 and were used for internal debugging and visualization. Since December 2017 the project is developed in our internal GitLab but only as a "tinkering project" and not as something productive. With the map you could (for example) after bigger network changes or new dormitories check for the network structure and if somewhere fibers are missing or connected in a wrong way.
Meanwhile the project has evolved and several people are using it for debugging or just to understand how our network works.
Thats the reason why we automated it now, "brighten it up" and added several features. Now you can also see the speed of links between devices in colorcode or differentiate hosts by type. The last was quite important as the map became crowded after we added our wireless access points to it.
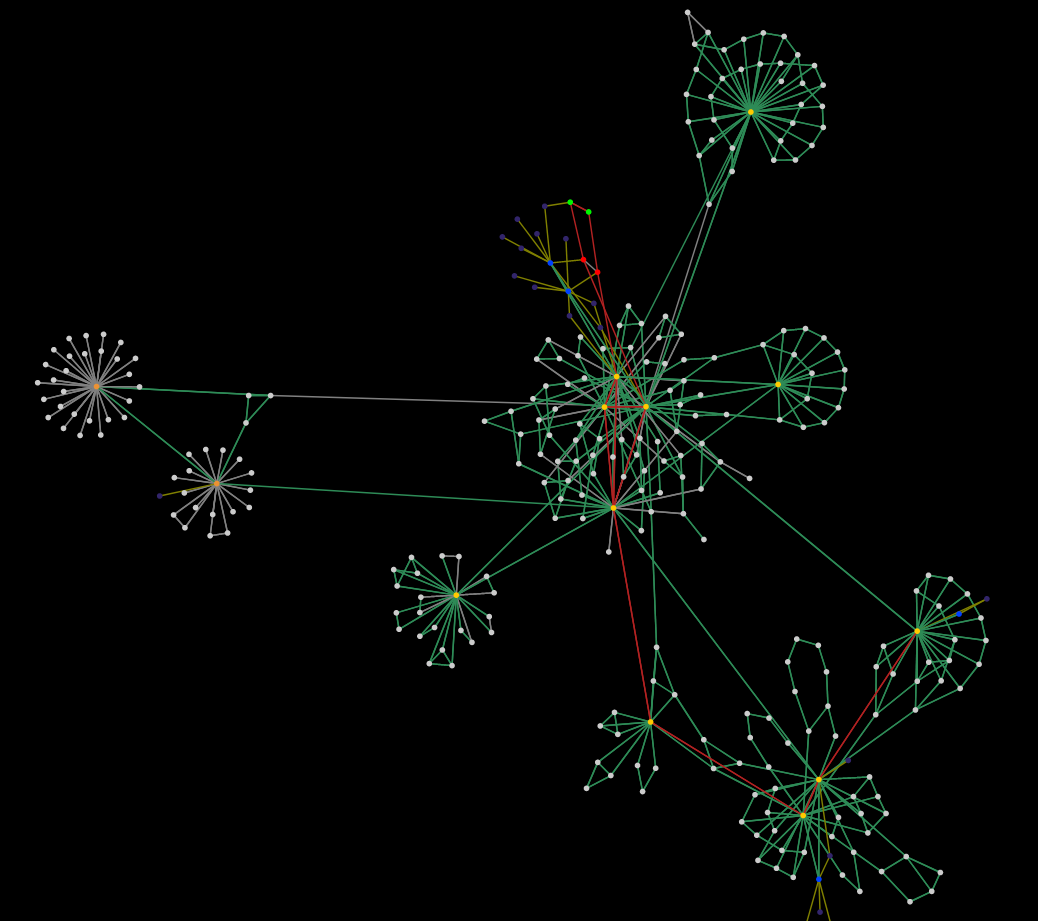
Cutout of the network map
So for transparancy reasons (and so everybody can have a look how our network is connected) we now published the map on our Website. Direct Link
Of course there are still some small bugs we hope to eliminate as soon as possible.
Thanks to all of our members who helped in any way to realize this project.
Do you want to participate in taking care of such problems in the future? For our network to run smoothly there are a lot of different things to do: management of the equipment (including buying new stuff and getting service), taking care of servers for the network or additional services, debugging problems like this or connecting new dormitories to our network.
If you want to volunteer, it doesn't matter if you are a pro or a starter: Selfnet offers the opportunity to learn everything required. If you are interested in technical stuff, programming, public relations, project management or anything else: We would be glad to welcome you in our team! Just visit our support hours (once the office hours are re-opened).
The Selfnet-Team
Deutsche Übersetzung
Die Selfnet Netzwerk-Karte
Mittlerweile ist unsere interaktive Netzwerkkarte öffentlich geworden, mit der man den momentanen Zustand unseres (internen) Netzes besser nachvollziehen kann.
Wir möchten euch aber auch den Weg aufzeigen, wie diese Entwicklung über die Jahre entstanden ist.
Vor einigen Jahren auf einer Gulasch-Programmier-Nacht in Karlsruhe eine Javascript-Library (VivaGraphJS zur Graphendarstellung, die unter anderem in der Moleküldarstellung genutzt wurde, anzupassen um Netzwerke zu visualisieren.
Ursprünglich war der Gedanke nur, dass man mal "sieht" wie unser Netzwerk eigentlich aussieht. Das die Karte lustig durch die gegend "gebobbelt" werden konnte hat den Spaßfaktor natürlich erhöht :)
Einige Jahre später hat ein anderes unserer Mitglieder ein Script in Perl gebaut (weil er Perl lernen wollte), dass unser Netzwerk automatisch untersucht und Nachbarbeziehungen erfasst.
Dies funktionierte über Anfragen an unsere Geräte per SNMP, welche die Nachbarbeziehungen per LLDP abgefragt haben.
SNMP (Simple Network Management Protocol) ist dabei ein einfaches Netzwerkverwaltungsprotokoll, dass wir eigentlich benutzten um zum Beispiel Auslastungsinformationen wie Temperatur, CPU-Last oder Traffic auszulesen. Dieses Protokoll kann aber (mit den richtigen Benutzerdaten) auch andere Informationen abrufen.
Diese Informationen umfassen die LLDP (Link Layer Discovery Protocol) Daten des Gerätes. LLDP funktioniert dabei zwischen konfigurierten Geräten auf einer der untersten Netzwerkebenen, noch bevor IP-Adressen benutzt werden und tauscht zwischen verbundenen Geräten Informationen aus. Diese Informationen beinhalten zum Beispiel den Hostnamen oder auch den angeschlossenen Port. Dies kann daher auch dafür genutzt werden, physikalische Fehler in Verbindungen zu finden.
Ein Beispiel
Local Interface Parent Interface Chassis Id Port info System Name
ge-0/1/2.0 - xx:xx:xx:xx:xx:xx ge-0/1/0.0
Diese Daten wurden ursprünglich dann nur genutzt um fehlende Verbindungen oder fehleranfällige Knotenpunkte zu finden (per Script).
Die letzten Jahre wurde dies dann "verheiratet". Die ersten Versionen sind von 2016 und wurden dann fürs interne Fehlersuchen und zum visualisieren genutzt. Seit Dezember 2017 ist dies Projekt bei uns im internen Gitlab verzeichnet, allerdings eher als "Bastelprojekt" und nicht als "produktives Projekt". Mithilfe der Karte konnte man beispielsweise nach großen umbauten oder neuen Wohnheimen feststellen, ob irgendwo Glasfasern falsch gesteckt sind oder Verbindungen noch fehlten.
Mittlerweile hat sich das Projekt aber soweit entwickelt, dass mehrere Personen das zum debugging oder zum verstehen des Netzwerkes genutzt haben.
Daher haben wir das Projekt jetzt automatisiert (das man es als Script ausführen kann) und auch etwas "aufgehübscht" und weitere Features eingebaut. So kann man jetzt auch per Farbe die Geschwindigkeit der Verbindungen erkennen, Hosts nach Typ erkennen oder einzelne Sachen nacheinander einblenden. Letzteres war ein wichtiger Punkt nachdem wir angefangen haben die WLAN-Accesspoints aufzunehmen, da die Karte einfach unglaublich komplex wurde.
Ausschnitt der Netzwerkkarte
Aus Gründen der Transparenz für unsere Mitglieder (und damit jeder mal sehen kann wie das alles aussieht) haben wir die Karte nun auf unserer Webseite eingebunden. Direkter Link
Natürlich gibt es noch einige kleinere Probleme, die wir hoffen bald beheben zu können.
Wir danken hiermit allen Mitgliedern, die bei der Realisierung des Projektes beteiligt waren.
Möchtest du in Zukunft bei Selfnet mitmachen und dich ehrenamtlich um solche und andere interessante technische Dinge kümmern? Um das Wohnheimsnetz ordentlich zu betreiben gibt es viele verschiedene Dinge zu tun: Verwaltung der Hardware (inkl. Neukauf von Hardware und mit dem Hersteller bezüglich Service arbeiten), Verwaltung von Servern und anderen Netzwerkdiensten, Analyse von Problemen oder neue Wohnheime an das Wohnheimnetzwerk anschließen.
Wenn du mitmachen möchtest geht es nicht um Vorwissen. Wichtiger ist es Spaß zu haben und noch etwas sinnvolles/praktisches neben dem Studium zu tun. Wenn du dich für Technik, Softwareentwicklung, Öffentlichkeitsarbeit, Projektmanagement oder vieles andere interessierst: Wir freuen uns dich bei uns begrüßen zu dürfen! Besuche einfach eine unserer Sprechstunden, (sobald diese wieder stattfinden.).
Das Selfnet-Team